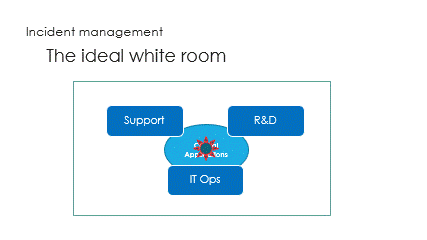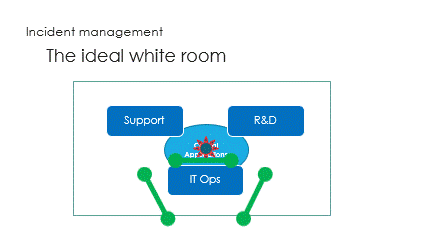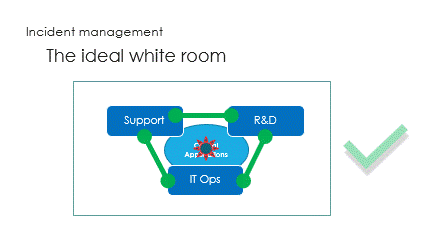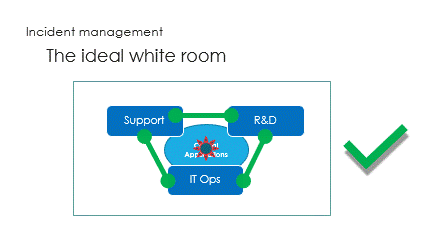
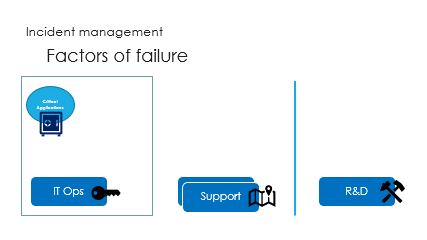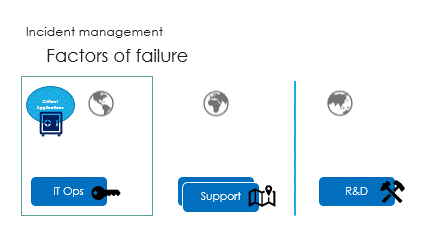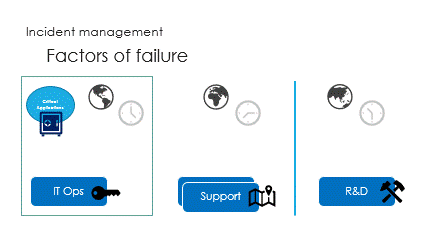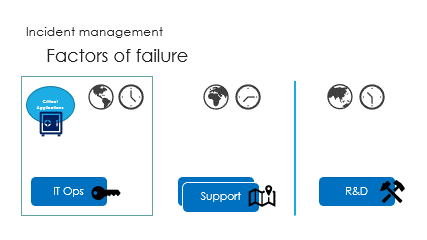
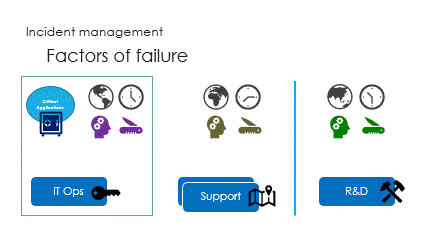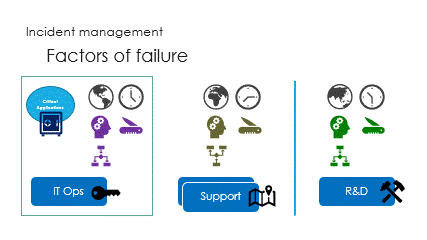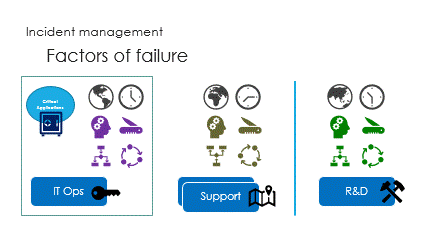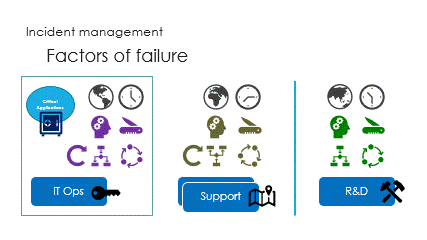
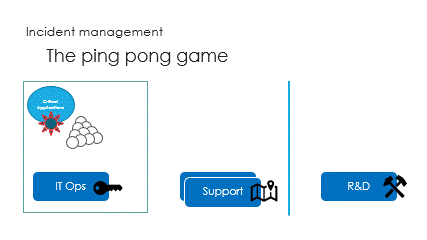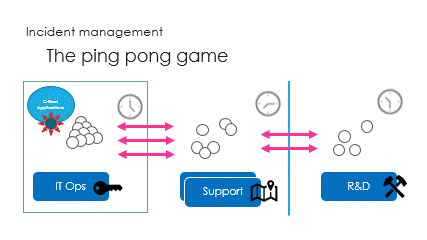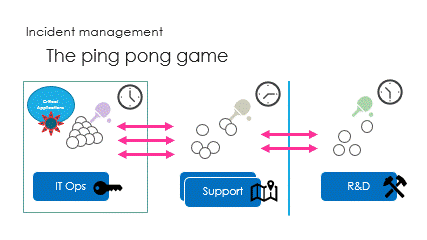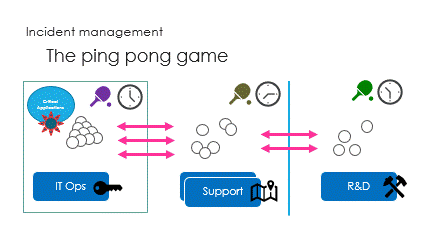
And finally are the interactions, called the ping pong game.
Successive round trips, taking time to access partial information,
hoping R&D will get the right ball to catch the issue.
Some people do play the watch, asking useless questions
while waiting for knowledgeable people to appear.
IT Ops see the incident signs and impacts, with some delay.
Challenge is to react in the right way : support guidance is vital here.
Unfortunately, the ping pong game makes it very slow.
Investigation procedures should be as light as possible.
Risky restart is often the solution.